


Come vedere e salvare i cambiamenti di un sito web negli anni
27 gennaio 2021
1611752229000
Sono diverse le funzioni che permettono di visualizzare le precedenti versioni di una pagina web, dalla funzione di cache Google alla vera e proprio macchina del tempo di internet: WaybackMachine!
In questo articolo tratteremo di Archivi Web: delle enormi banche dati dove è possibile salvare in maniera permanente interi siti internet. Impareremo come recuperare informazioni rimosse dai siti e come vedere la storia nel corso degli anni dei più importanti siti internet.
Il principio di funzionamento di un archivio Internet è abbastanza semplice: qualcuno (un qualsiasi utente) seleziona una pagina da salvare. L'Archivio Internet lo scarica, inclusi testo, immagini e stili di progettazione, ed infine lo salva. Su richiesta, la pagina salvata può essere visualizzata nell'Archivio Internet, a prescindere se la pagina originale è cambiata o se il sito è stato cancellato.
Gli archivi internet memorizzano diverse versioni della stessa pagina, come se scattassero un'istantanea in momenti diversi. Grazie a questo, è possibile tracciare lo storico dei cambiamenti di un sito o di una pagina vecchia durante il passare degli anni.
#QUALI ARCHIVI INTERNET ESISTONO?
I principali archivi internet sono 2:
- https://web.archive.org/
- http://archive.md/ (spesso si trova come https://archive.ph/ o https://archive.vn/)
Il più popolare dei due è il primo, noto anche come Wayback Machine.
#COME UTILIZZARE UN ARCHIVIO INTERNET
Per salvare una pagina web ci basta andare su https://archive.org/web/, inserire l'indirizzo che vogliamo congelare e cliccare il pulsante SAVE PAGE. In questo modo tutte le informazioni di quella pagina web verranno salvate.
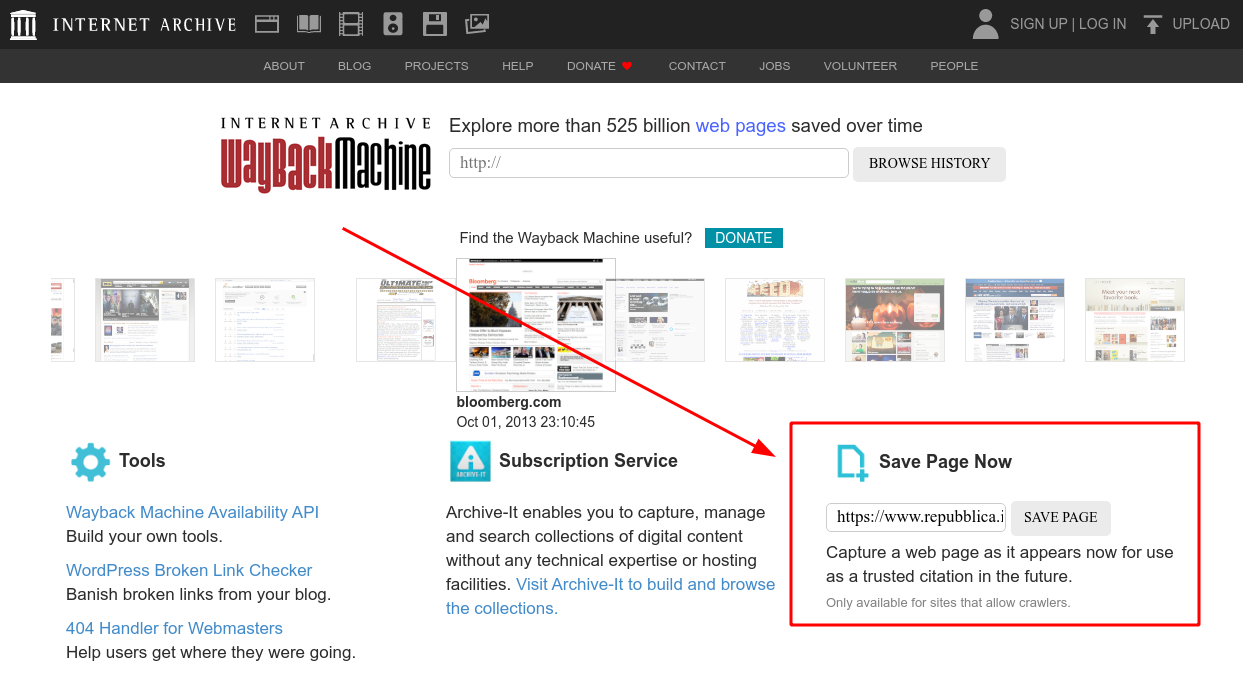
In questo caso abbiamo scelto di salvare un articolo della sezione scienze del famoso giornale italiano La Repubblica. Dopo qualche secondo il sito ci rimanderà ad una pagina come questa
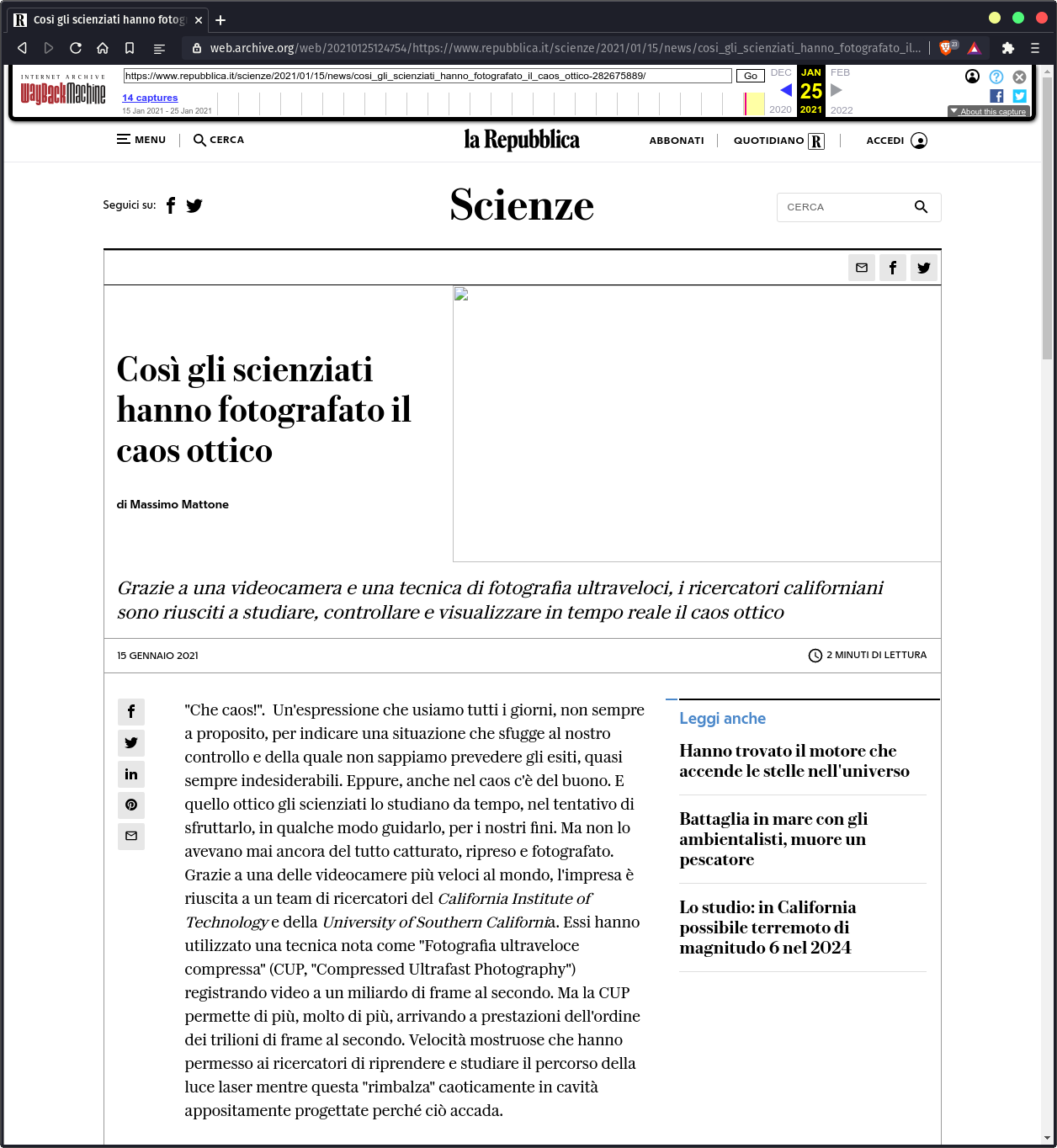
Questo articolo di La Repubblica resterà salvato anche se la redazione del giornale dovesse decidere di eliminarlo. È possibile raggiungerlo tramite questo link
È possibile che qualcuno prima di noi abbia già creato delle istantanee di un sito o di una determinata pagina web. Per visualizzare la "cronologia" di un determinato indirizzo rechiamoci nuovamente sul sito https://archive.org/web/ ed inseriamo nella barra superiore l'indirizzo desiderato
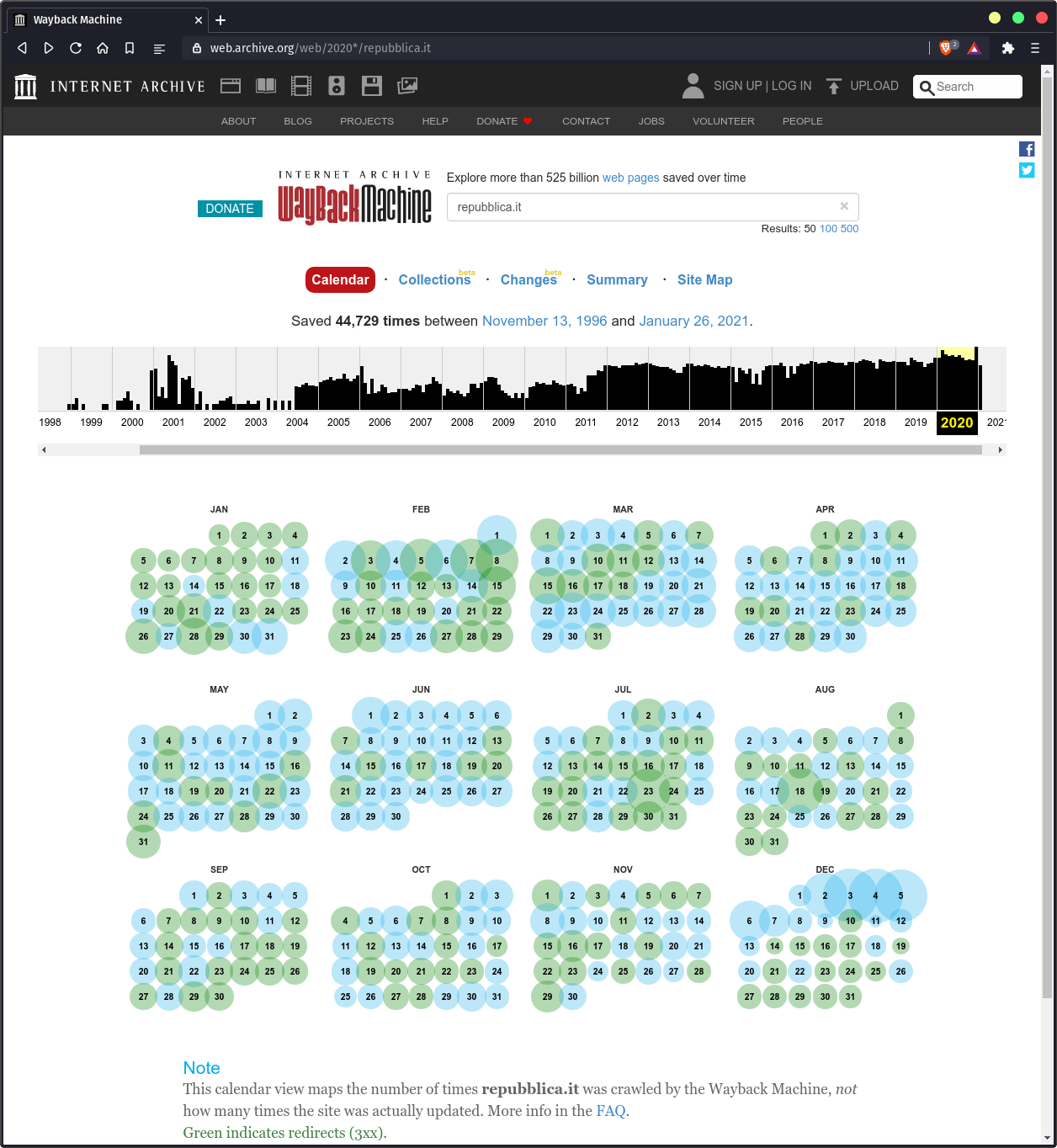
Cerchiamo di capire come muoverci per trovare l'informazione che cerchiamo. Come prima cosa, in alto possiamo scorrere un barra temporale orizzontale. Questa ci permette di selezionare l'anno in cui vogliamo cercare uno "snapshot". Come possiamo notare il sito repubblica.it è online da oltre 20 anni, il primo snapshot risale al 12 Dicembre 1998. Curiosi di vedere come era strutturato il sito a quel tempo? Clicchiamo questo link
Una volta scelto l'anno, ad esempio il 2020, avremo un calendario completo dove ogni giorno può essere colorato di 5 colori diversi (di norma sono sempre 2 o 3)
- Blu: Quando un giorno dell'anno è cerchiato di blu, l'archiviazione di una determinata pagina da parte è andata buon fine.
- Verde: Questo colore indica un reindirizzamento 3xx. Ovvero, la pagina web esiste ancora ma l'URL è diverso (ad esempio per colpa di un titolo modificato).
- Arancione: Anche se raro, potrebbe apparire questo colore. In questo caso vuol dire che lo stato è 4xx: c'è un errore lato client, ad esempio pagina non trovata.
- Rosso: Quando incontriamo un giorno cerchiato di rosso, vuol dire che l'archivio internet ha avuto un problema di server e quella pagina non è disponibile
- Bianco: Quando un giorno della settimana non è cerchiato, vuol dire che non è stato eseguito nessuno snapshot in quella data. Non avremo modo di recuperarla (o quasi)
Supponiamo ad esempio di voler vedere gli snapshot effettuati giorno 2 dicembre 2020 sul sito repubblica.it, per farlo basta cliccare sul giorno nel calendario e scegliere quello l'istantanea che preferiamo
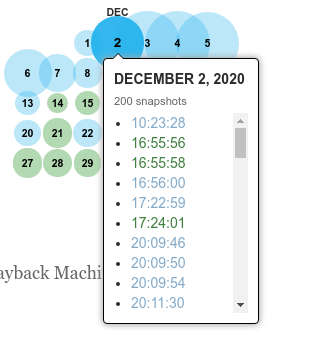
In questo giorno, sono stati effettuati 200 snapshot all'indirizzo repubblica.it.
#SOMMARIO
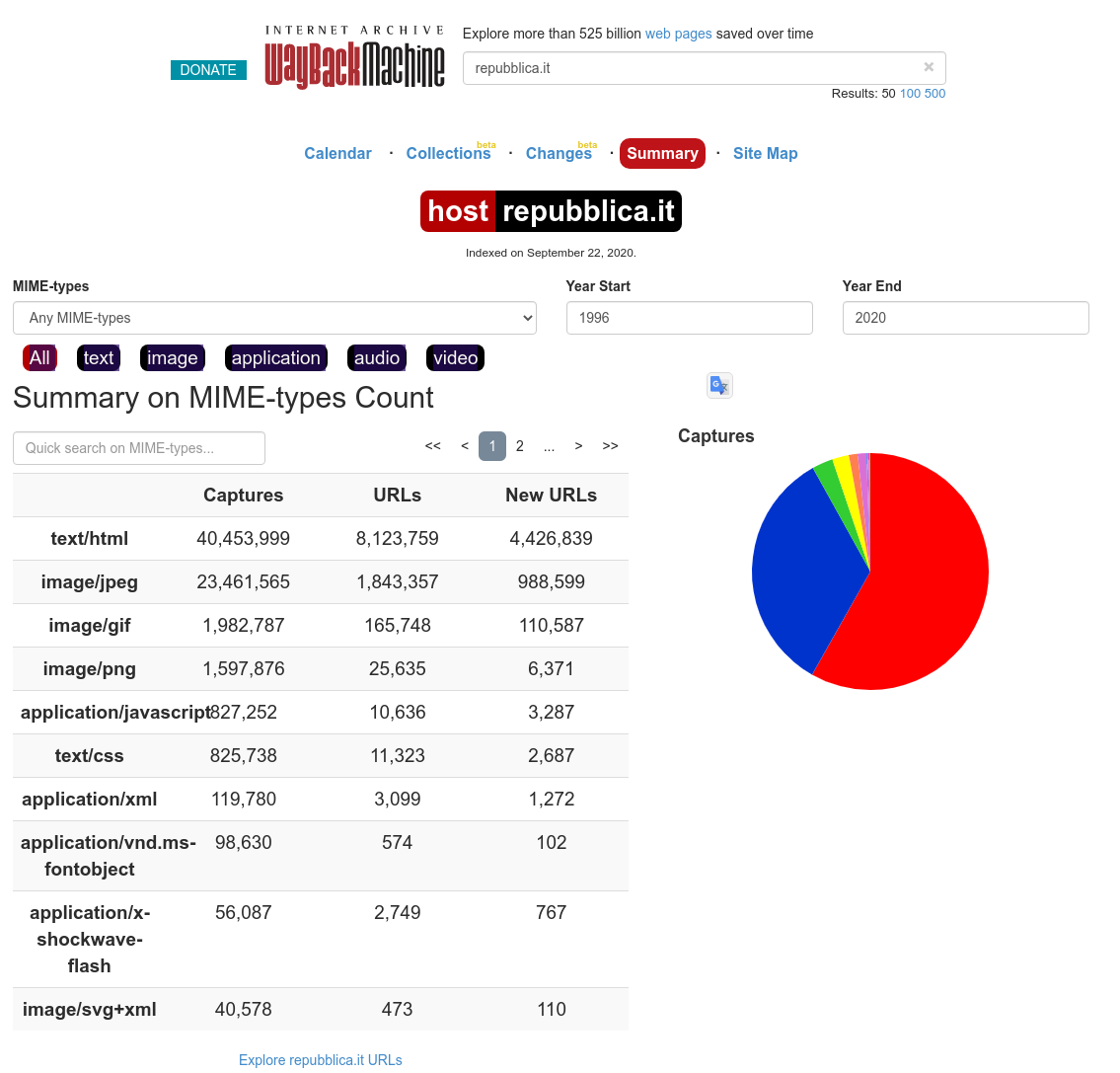
È pure presente una sezione che riassume e analizza tutti gli snapshot che sono stati effettuati, categorizzandoli per formato. Per visualizzare il sommario di una pagina web rechiamoci a questo indirizzo e nella barra di ricerca inseriamo l'URL desiderato
Sommario: https://web.archive.org/details/
Ad esempio, considerando sempre repubblica.it vedremo queste informazioni
#SE UNA PAGINA NON È PRESENTE NELL'ARCHIVIO?
Gli archivi internet salvano solo le pagine che gli utenti chiedono di salvare: non hanno ancora strumenti automatizzati per salvare in automatico nuove pagine e link appena create. Per questo motivo, è possibile che la pagina a cui siamo interessati sia stata cancellata prima che qualcuno potesse salvarla in un archivio web.
Tuttavia, possiamo utilizzare i servizi dei motori di ricerca che scansionano continuamente il web alla ricerca di nuove pagine. Possiamo sperare, conoscendo l'indirizzo, di trovare la pagina desiderata nella cache di Google ad esempio.
Utilizzando un qualsiasi browser che abbia come motore di ricerca Google scriviamo nella barra
cache:URLse volessimo solo vedere la versione testuale della pagina formattiamo in questa maniera il link
http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0Se volessimo solo vedere la sorgente della pagina formattiamo il link come
http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1Dove ovviamente al posto di URL dobbiamo inserire l'indirizzo desiderato
#CONCLUSIONE
Internet è un mondo così vasto che ormai niente può restare inosservato. Tramite un archivio web abbiamo in mano una macchina del tempo: possiamo ripercorrere, nel caso di un giornale ad esempio, la storia degli ultimi 20 anni di un paese.