


Intel Core Ultra 9 285k - Recensione
24 ottobre 2024
Intel cambia tutto: nome, socket e architettura. Con Arrow Lake la Casa Blu porta la sua tecnologia Foveros 3D anche nelle CPU Desktop, con l'obiettivo di ottimizzare i consumi il più possibile, mantenendo della prestazioni in linea con le generazioni precedenti.
L’architettura di Arrow Lake #
Dopo Alder e Raptor Lake, Arrow Lake è la terza iterazione desktop dell’architettura ibrida di Intel, composta da Performance core (P-core) ed Efficiency core (E-core). Nei Core Ultra 200 troviamo i P-core “Lion Cove” e gli E-core “Skymont” ed entrambi sono caratterizzati da alcune differenze sostanziali rispetto ai precedenti Raptor Cove e Gracemont. Questi due core hanno fatto il loro debutto nei processori mobile Lunar Lake (Core Ultra 200V) poche settimane fa.
Lion Cove #
I nuovi P-core Lion Cove vedono un moderato incremento dell’IPC, circa il 9% stando ad Intel, dovuto principalmente ad una ristrutturazione del sistema di cache, un front end più ampio con migliori capacità predittive, un engine out-of-order modificato e ampliato e, cosa più evidente, alla rimozione dell’ HyperThreading.
Intel ha rielaborato il sottosistema di cache a livello di core aggiungendo una cache dati intermedia tra i 48 KB di L1 e il livello L2. La cache L1D originale è ora chiamata internamente L0D e la L1D si riduce a 192 KB. La cache L2 aumenta a 3 MB, mentre la cache L3 totale rimane invariata rispetto a Raptor Lake. L’out-of-order engine di Lion Cove è stato “allargato” e sono aumentate le porte di esecuzione e la finestra delle istruzioni profonde. Inoltre è stato partizionato in domini di esecuzione integer (INT) e vettoriali (VEC) indipendenti: questo tipo di partizionamento consente l’espandibilità in futuro, la crescita indipendente di ciascun dominio e la riduzione del consumo energetico durante i carichi di lavoro specifici di quel dominio.

La rimozione dell’Hyper-Threading è uno dei motivi potenziali del miglioramento dell’efficienza energetica e delle prestazioni single thread; oltre a consentire una riduzione dell’area per singolo core, permette ad ognuno di essi di “focalizzarsi” al meglio su alcuni tipi di calcoli a bassa latenza e basso throughput, non dovendo gestire due thread in contemporanea. Miglioramenti dovuti alla disattivazione dell’HT/SMT si sono già visti in passato, sia su Intel che su AMD, in diversi giochi ed applicativi molto dipendenti dalle prestazioni dei singoli thread. Infine, per spremere gli ultimi punti percentuali di prestazioni a pari potenza, gli intervalli di regolazione della frequenza sono stati resi più granulari, passando da 100 a 16,67 MHz.
Skymont #
Intel punta sicuramente a compensare il calo di prestazioni multi threaded dei P-core, privati dell’HT, con un notevole potenziamento degli E-core.
I core Skymont presentano un’architettura di decodifica significativamente più ampia, con uno stadio di decodifica che include il 50% in più di cluster di decodifica rispetto alle generazioni precedenti. Ciò è supportato da una coda di μ-OP più ampia, che ora contiene 96 voci. Intel ha migliorato il motore di esecuzione out-of-order raddoppiando l’ampiezza di allocazione e ritiro, che dovrebbe ridurre la latenza complessiva e minimizzare lo stallo per le dipendenze dai dati.
È dotato di un buffer di riordino di 416 voci, rispetto alle 256 precedenti; e anche le dimensioni dei file di registro fisico (PRF) e di INT, MEM e VEC sono state rese più profonde. La cache L2, pur rimanendo di 4 MB, ha ricevuto un raddoppio di banda per poter stare al passo delle prestazioni migliorate degli E-core.
A causa della loro natura a bassa potenza e ampia diffusione (dai SoC mobile da pochi watt a CPU desktop e server da oltre 250 W), gli E-core Skymont sono progettati per essere molto flessibili, con un certo vantaggio rispetto alle precedenti architetture. Rispetto a Raptor Cove (sì, i precedenti P-core), Skymont offre prestazioni integer e in virgola mobile migliori del 2% nei carichi di lavoro single thread, con un consumo energetico quasi identico a Raptor Cove. Rispetto ai precedenti E-core, i Gracemont, l’IPC è aumentato mediamente di ben il 32%.
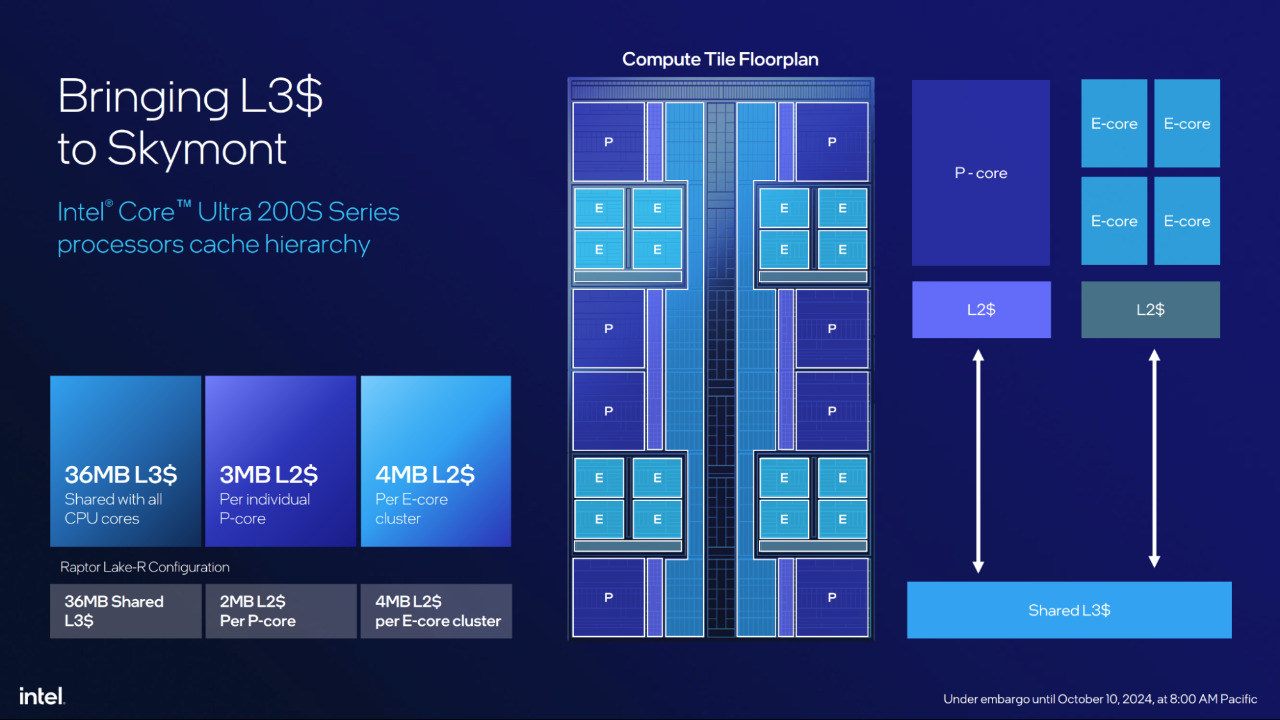
A collegare P ed E core c’è sempre il Ring Bus, che però ora mette in comunicazione i cluster in maniera diversa. Mentre prima i due tipi di core erano alle due estremità dell’anello, ora ogni cluster di 4 E-core è posto tra una coppia di P-core e tutti accedono alla stessa cache L3 di 36 MB. Questa scelta deriva dal nuovo ordine di priorità di assegnazione dei thread: mentre prima un thread veniva assegnato prima ai P-core e poi delegato agli E-core in caso di necessità di potenze di calcolo inferiori, ora l’iter è opposto, assegnando prima il lavoro ai cluster di E-core per poi affidarlo ai P-core in caso di bisogno. Questa soluzione dovrebbe ridurre i consumi con carichi bassi o altalenanti. Intervallare i diversi tipi di core dovrebbe quindi diminuire la latenza in caso di cambio di affidamento delle operazioni, oltre che a migliorare la gestione delle temperature allontanando tra loro i P-core.
Il chip #
Dopo i “test” con Meteor e Lunar Lake, Intel fa arrivare Foveros anche su desktop, con ovviamente alcune caratteristiche differenti date dalle necessità e dalle diverse potenze assorbite.
A fare da interfaccia tra package e chiplet c’è una base tile di circa 300 mm², l’unico die di Arrow Lake prodotto da Intel su nodo 22 FFL, che a discapito del nome assomiglia più al nodo a 14 nm ma appositamente meno denso per massimizzare la resa e le caratteristiche di potenza e integrità di segnale. Tutti gli altri chiplet sono prodotti da TSMC su diversi nodi.

Il Compute tile, dove risiedono i core descritti precedentemente, è prodotto su nodo N3B ed è, comprensibilmente, il più grande della CPU, con un’area di circa 115 mm². Il nodo N3B è più denso di N4, N4P ed N4X, usati ad esempio per Zen 5 mobile e per le GPU Ada, ma è abbastanza simile in termini di prestazioni e consumi, fornendo solo un piccolo vantaggio ad Intel.
Immagine da @Madness727 e annotazioni di HighYield
Il secondo chiplet più grande è il SoC tile, da circa 86 mm², prodotto su N6. Svolge la funzione di “raccordo” tra gli altri chiplet ed ospita sezioni fondamentali come i controller di memoria, PCIe, USB e connettività, oltre alla sezione di output video e alla NPU. Ad esso è collegato un altro chiplet di 24 mm², l’I/O tile, prodotto sullo stesso nodo e che ospita le interfacce fisiche della sezione di input e output.
Curiosamente il GPU tile è il chiplet più piccolo, circa 23 mm², ospita 4 Xe cores ed è prodotto su nodo N5. È la prima iGPU desktop di Intel a supportare il raytracing, anche se ovviamente non è abbastanza potente per sfruttarlo effettivamente; il supporto è derivante dalla presenza delle unità di raytracing, una per Xe core, interne all’architettura Xe-LPG e alle Intel Arc.
Vi sono due piccoli tile di riempimento agli angoli, che hanno solo funzioni strutturali e termiche. Il chip è infine saldato su un IHS leggermente modificato rispetto a quelli delle due generazioni precedenti, cosa che dovrebbe alleviare il fenomeno del “piegamento” del package già notato sulla 12a generazione.
Immagine di Tony Yu di ASUS
Intel Core Ultra 9 285K #
Il nuovo Intel Core Ultra 9 285K arriva sul mercato con alcune differenze rispetto alle generazioni precedenti: è stato completamente rimosso l’hyperthreading, creando pertanto un processore 24/24 diviso tra 8 core di tipologia P e 16 core di tipologia E.

A questo si aggiungono una GPU integrata con 4 Compute Units, una NPU dedicata ai calcoli IA da 13 TOPs e una frequenza massima in Turbo Boost di 5.7 GHz sui P-Core.
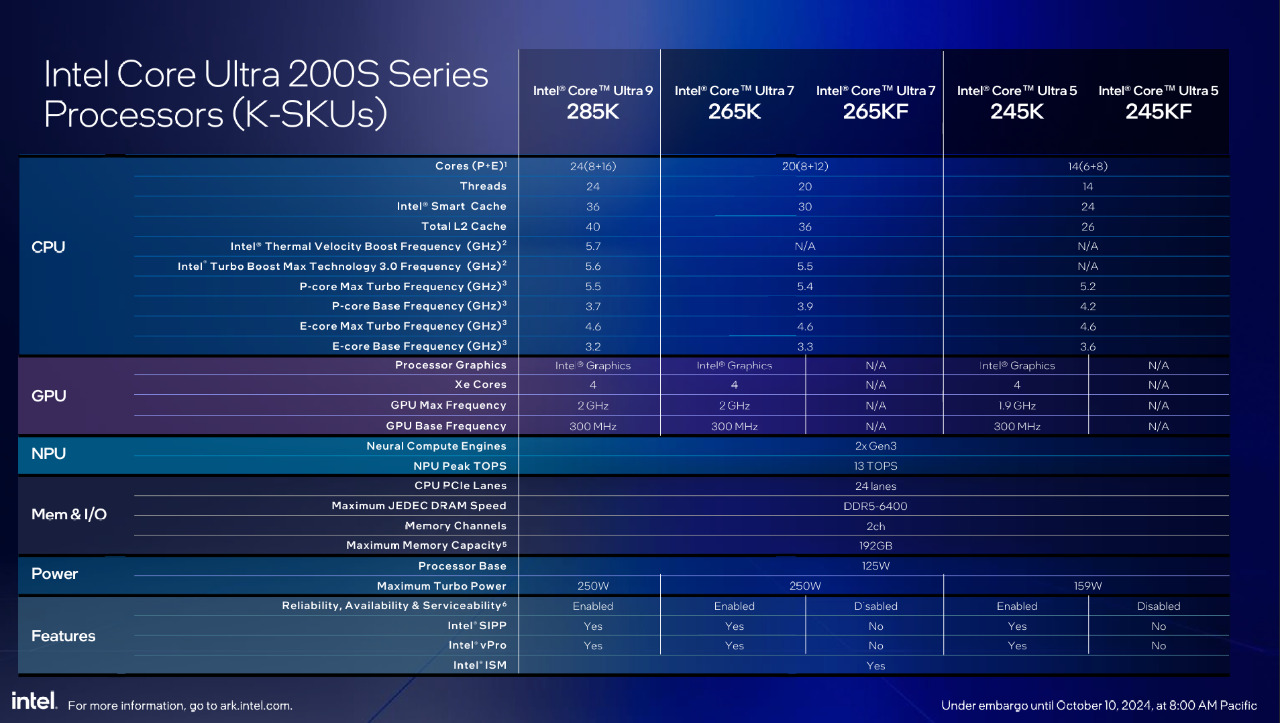
I Power Limit sono stati ridefiniti, con un profilo base che raggiunge “solamente” 250W per i due Intel Core Ultra 7 e Intel Core Ultra 9 e impone strettamente questo valore, a differenza degli i9 13900K e i9 14900K, capaci di raggiungere anche i 341W totali.
Piattaforma: serie 800 - ROG Maximus Z890 HERO #

Per i test stiamo adoperando una ROG Maximus Z890 HERO, nuova scheda madre con supporto socket LGA 1851, non compatibile quindi con Intel 12th, 13th e 14th.
La nuova ROG Maximus Z890 HERO dispone di alcune nuove feature mutuate dalle X870E, come il nuovo sgancio rapido per WiFi, quello per SSD (solo nel primo slot) e la possibilità di estrarre la scheda video semplicemente tirando sul lato sinistro della stessa, senza blocchi meccanici come visto in precedenza o su modelli della concorrenza tutt’ora.

Come supporto SSD abbiamo 3 slot (M.2 1x 22110, 2x 2280) con supporto PCIe 5.0x4 e 3 slot M.2 2280 con supporto PCIe 4.0x4. Le GPU sono distribuite con una configurazione dall’alto al basso di PCIE 5.0x16, PCIe 4.0x16 e PCIe 4.0x1

In termini di fasi la ROG Maximus Z890 HERO dispone di una configurazione da 22+1+1+2.

A differenza della Z890 ACE vista nella recensione dell’Intel Core Ultra 265K, la ROG Maximus Z890 HERO riduce il numero di porte USB-C a 3 (2x40 Gbps, 1x10 Gbps) e anche il numero di USB A a 8 (3x10 Gbps, 4x5 Gbps, 1 BIOS). Viene meno anche il tasto personalizzabile, ma si aggiunge una seconda porta Ethernet, dividendo la configurazione in 2.5 Gbps e 5 Gbps. Infine, una HDMI.

Il nuovo chipset garantisce la possibilità di implementare un I/O veramente notevole, totalizzando assieme alla CPU 48 PCIe Lanes, di cui 20 PCIe 5.0 totali. A questo si aggiunge un limite di 14 USB 2.0, 10 USB 3.2 e 8 SATA 3.0.

Viene migliorato anche il supporto per quanto riguarda le memorie: fino a 48 GB per singolo DIMM, con una capacità massima totale di 192 GB, supporto ECC rinnovato e nuove tecnologie CUDIMM come le Gskill Trident FZ5 CK che abbiamo in test.
Sebbene da specifica il supporto ufficiale si fermi alle DDR5-6400, la maggior parte dei produttori di schede madri basate su chipset Z890 affermano di estendere il supporto anche oltre DDR5-8000: ovviamente si ricade nel territorio dell’overclock, in cui contano moltissimo la qualità dei chip montati sulle proprie RAM, le capacità del memory controller della CPU e il layout delle piste di collegamento tra CPU e RAM sulla scheda madre.

Prestazioni - Benchmark Sintetici #
Per quanto riguarda i benchmark abbiamo preso in analisi 4 processori a nostra disposizione, in quanto il 7900x e 7950x sono ancora difficili da reperire al momento della recensione. Abbiamo l’i5 12600k, l’i9 13900k, l’i9 12900k e il Ryzen 5 7600x. I due processori minori ci sono utili come “riferimento dal basso” per percepire la distanza (o dopo la vicinanza) di questi processori in vari aspetti prestazionali.
Testbench #
- Processori: Intel Core Ultra 7 265K, Intel Core Ultra 9 285K, i9 14900K, i9 13900K, i7 14700, Ryzen 9 9950X, Ryzen 9 7950X3D, Ryzen 7 7800X3D, Ryzen 7 7700x
- Schede madri: Z790 Pro Art Wifi, X670E-E ROG STRIX, X870E PRO ART, MSI Z890 ACE
- SSD: SK Hynix P41 Platinum 2 TB
- Dissipatore: MSI MAG CoreLiquid I360
- Case: Testbench aperta
- RAM: Corsair Dominator Titanium RGB 2x32 GB 6000 MHz
- PSU: FSP VITA 1000W
- Scheda video: RTX 4080 Super PRO ART
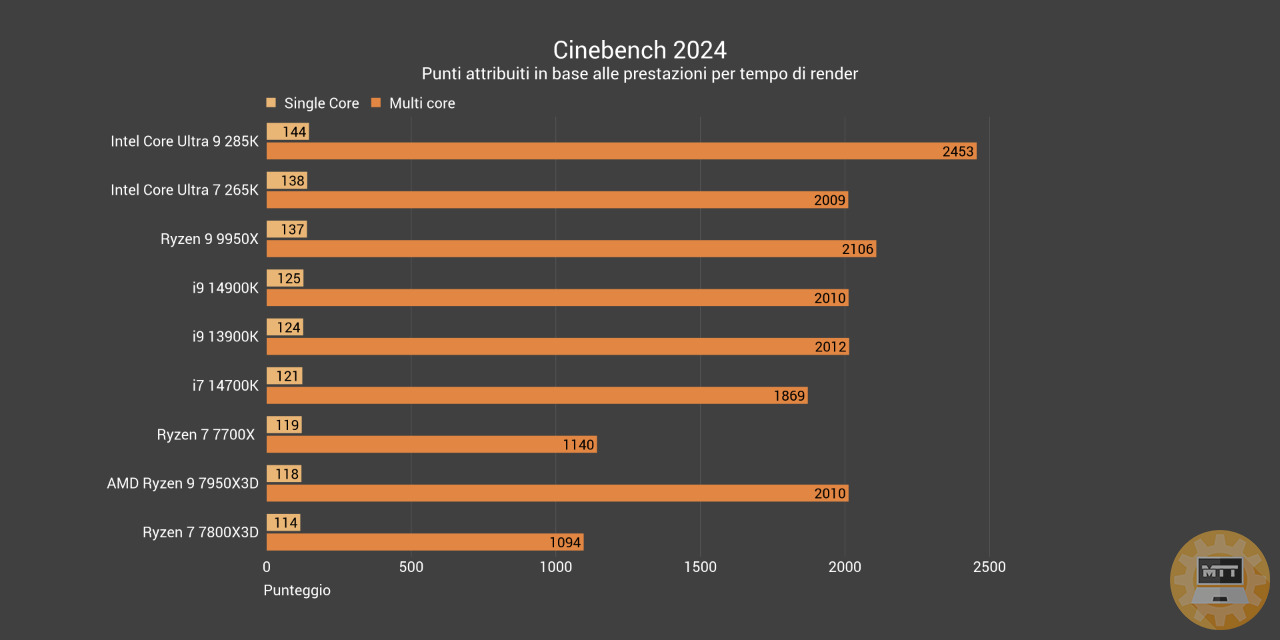
Cinebench R24 #
Cinebench è un benchmark reale che valuta le capacità hardware del computer. Si basa principalmente sulle prestazioni del processore e restituisce un punteggio che aumenta in base al miglioramento delle performance in single e/o multi core della cpu.
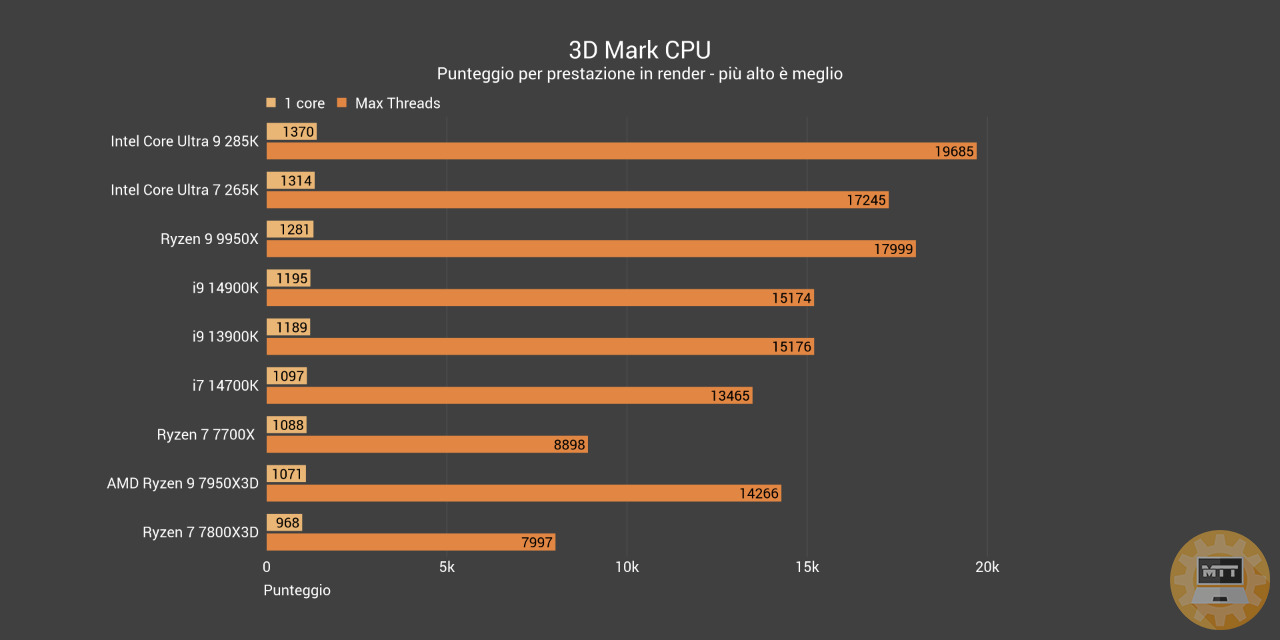
3D Mark CPU Test #
Il 3DMark CPU Profile introduce un nuovo approccio al benchmarking della CPU. Invece di produrre un singolo numero, il Profilo CPU di 3DMark mostra come le prestazioni della CPU aumentano in base al numero di core e di thread utilizzati.
Prestazioni - Benchmark Gaming 1080p #
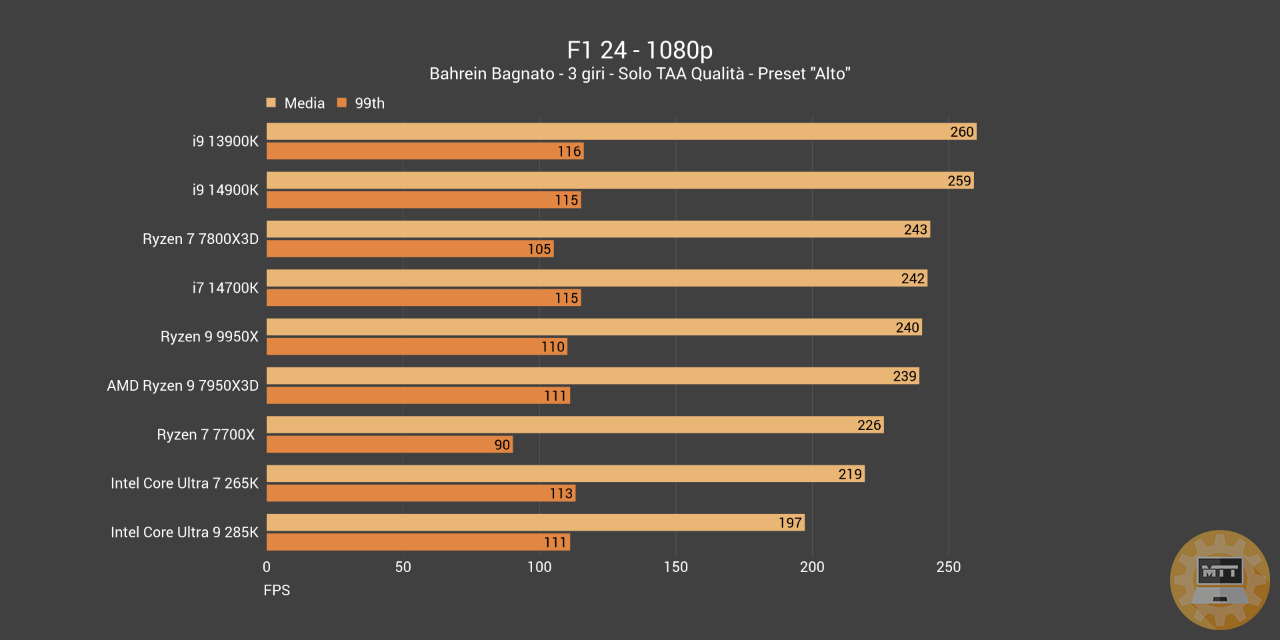
F1 24 #
F1 24 è un videogioco di corse sviluppato da Codemasters e pubblicato da EA Sports. È il quarto capitolo della serie distribuito da EA Sports, dopo aver acquisito Codemasters a metà febbraio 2021. Il gioco ha la licenza ufficiale per i campionati di Formula 1 e Formula 2 del 2024.
Age of Mythology: ReTold #
La Remastered di casa Microsoft riporta in auge lo strategico mitologico dei primi anni 2000, con una veste grafica migliorata e un po’ di supporti a tecnologie moderne. Il peso non è eccessivo, ma i processori sono in grado di fornirci una risposta a quale sia il migliore in questo contesto grazie al Benchmark Integrato.

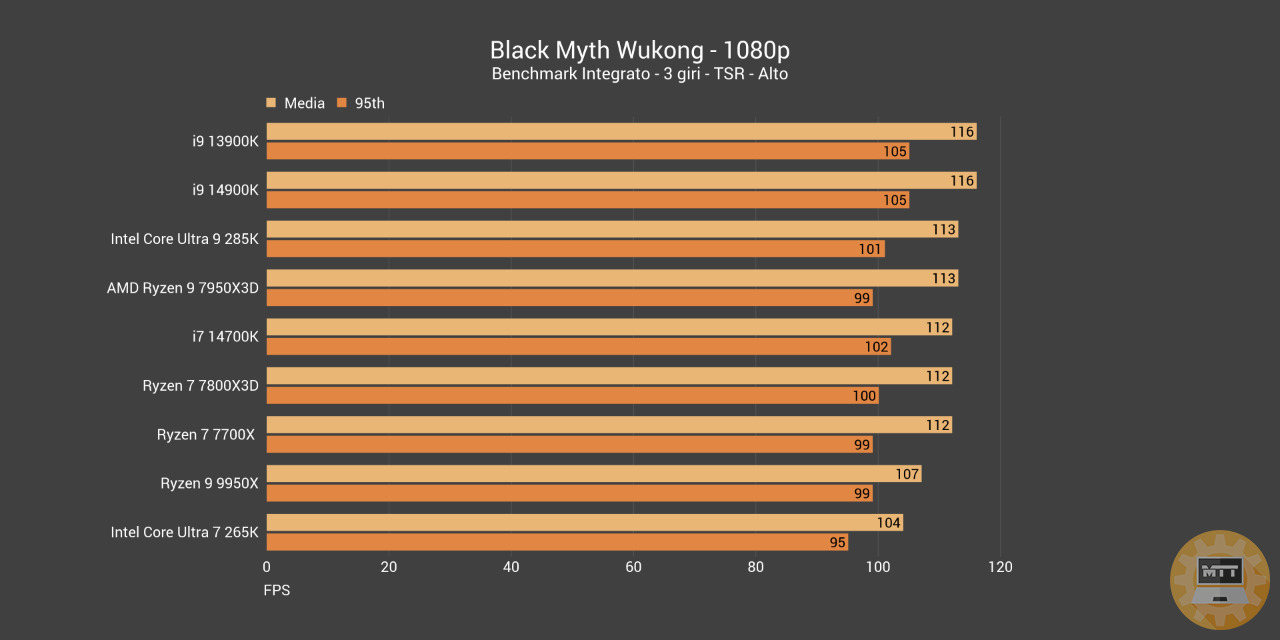
Black Myth Wukong #
Black Myth: Wukong è un gioco di ruolo d’azione del 2024 sviluppato e pubblicato da Game Science. Il gioco è ispirato al romanzo classico cinese Viaggio in Occidente e segue una scimmia antropomorfa basata su Sun Wukong del romanzo.
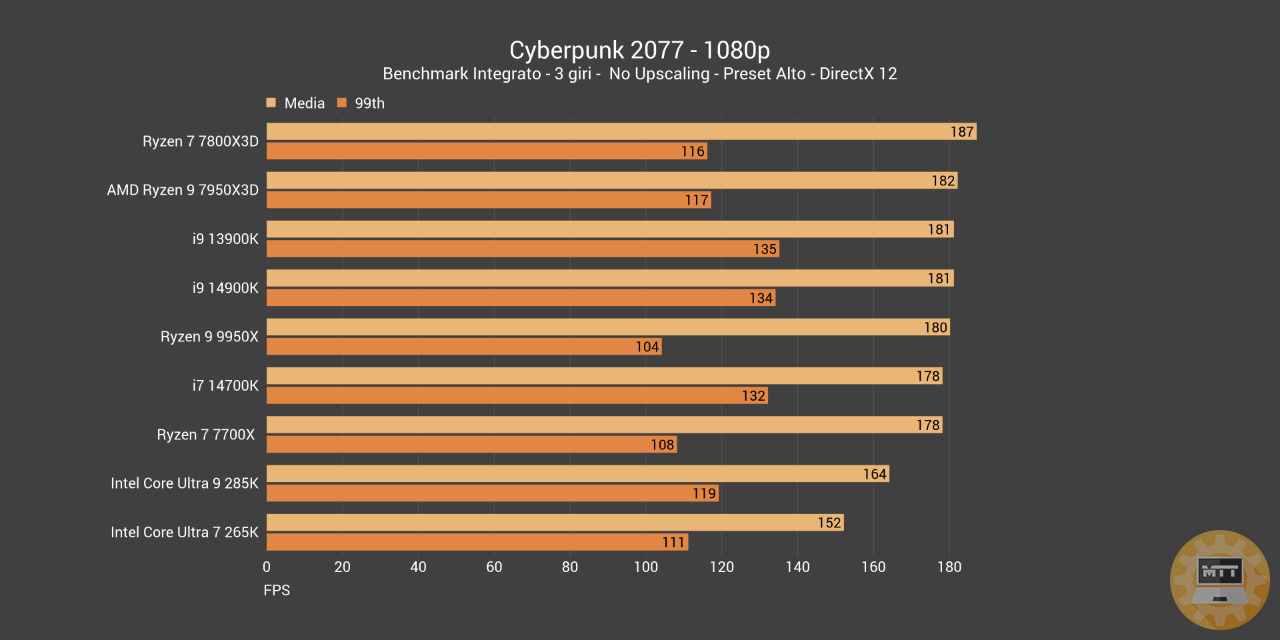
Cyberpunk 2077 #
Cyberpunk 2077 è un’avventura a mondo aperto ambientata a Night City, una megalopoli ossessionata dal potere, dalla moda e dalle modifiche cibernetiche. Questo titolo si è distinto particolarmente per la sete di aggiornamenti nei 2 anni di vita e ha implementato novità importanti come il DLSS 3.
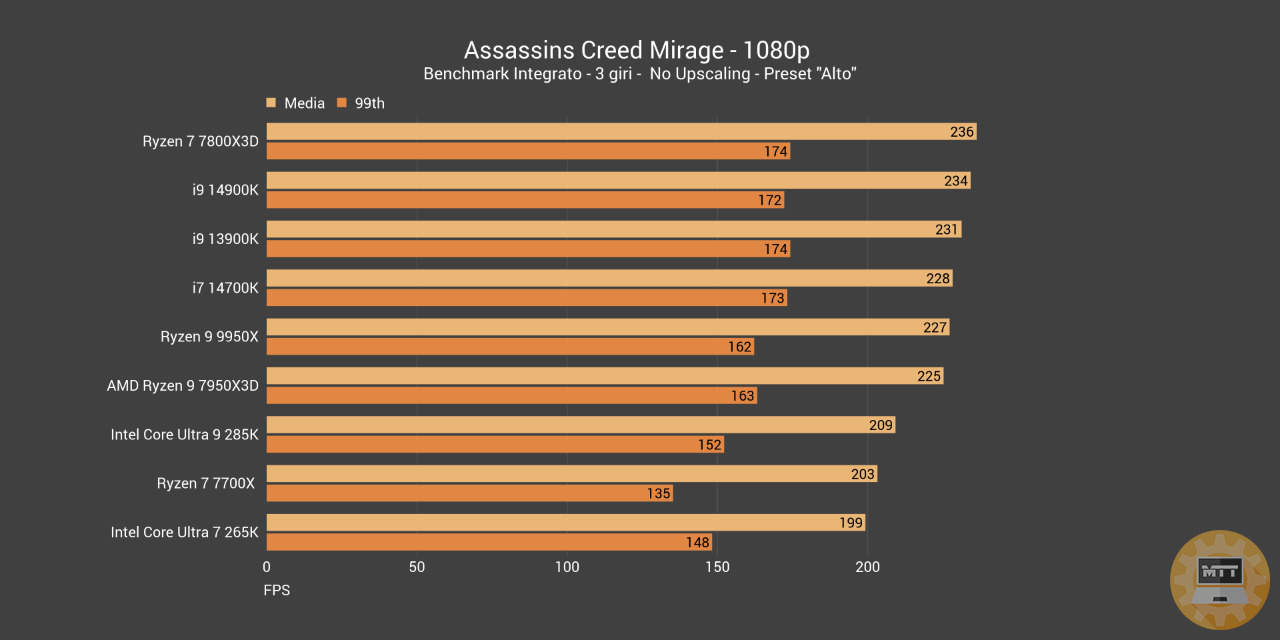
Assassin’s Creed Mirage #
Assassin’s Creed Mirage è un videogioco di azione e avventura sviluppato da Ubisoft Bordeaux e pubblicato da Ubisoft. È il tredicesimo capitolo principale della serie Assassin’s Creed e il successore di Assassin’s Creed Valhalla uscito nel 2020: inizialmente concepito come una grande espansione di quest’ultimo, è in seguito stato trasformato in un’avventura a sé stante.
Benchmark - Produttività #
Questa porzione di test valuta le prestazioni dei processori nel contesto del lavoro: abbiamo programmi di modellazione 3D, operazioni AI, Renderer, video e foto editing.
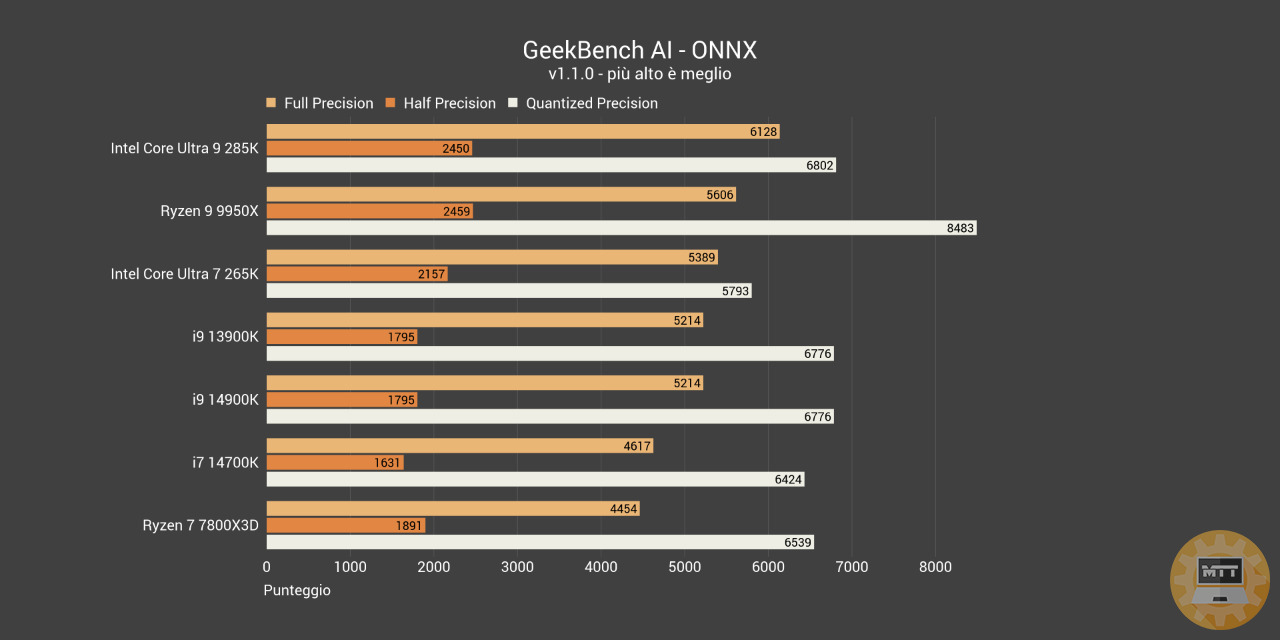
GeekBench AI ONNX #
Geekbench AI è un benchmark AI multipiattaforma che utilizza compiti di apprendimento automatico del mondo reale per valutare le prestazioni dei carichi di lavoro AI. Geekbench AI misura la CPU, la GPU e la NPU per determinare se il dispositivo è pronto per le applicazioni di apprendimento automatico all’avanguardia di oggi e di domani.
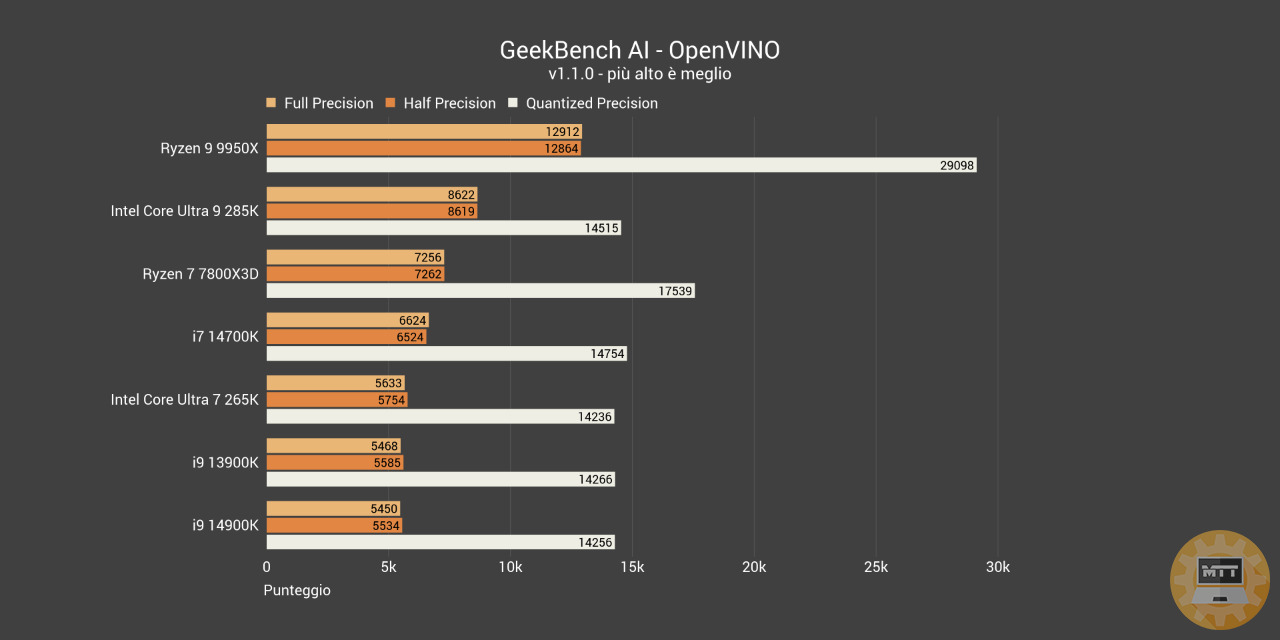
GeekBench AI OpenVino #
OpenVINO è un toolkit software open source per l’ottimizzazione e l’implementazione di modelli di deep learning. Consente ai programmatori di sviluppare soluzioni AI scalabili ed efficienti con relativamente poche righe di codice.
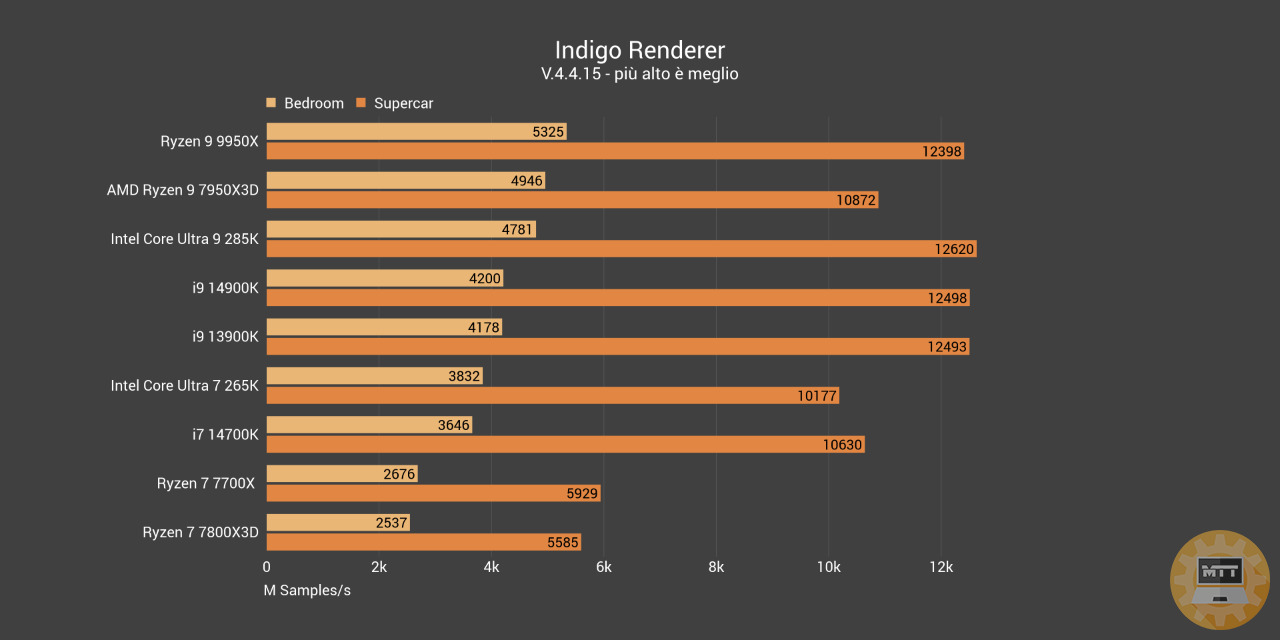
Indigo Renderer #
Indigo Renderer è un motore di rendering non approssimato sviluppato fin dal 2008 dalla neozelandese Glare Technologies fondata da Nicholas Chapman.
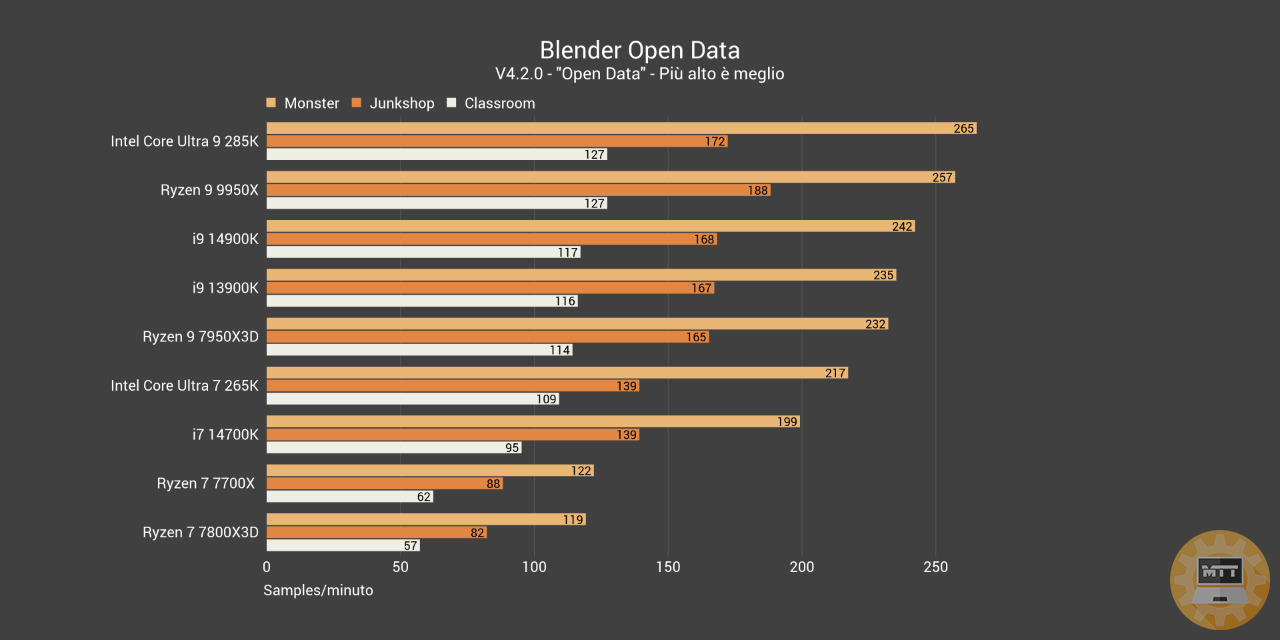
Blender Open Data #
Blender è un software libero e multipiattaforma di modellazione, rigging, animazione, montaggio video, composizione, rendering e texturing di immagini tridimensionali e bidimensionali.
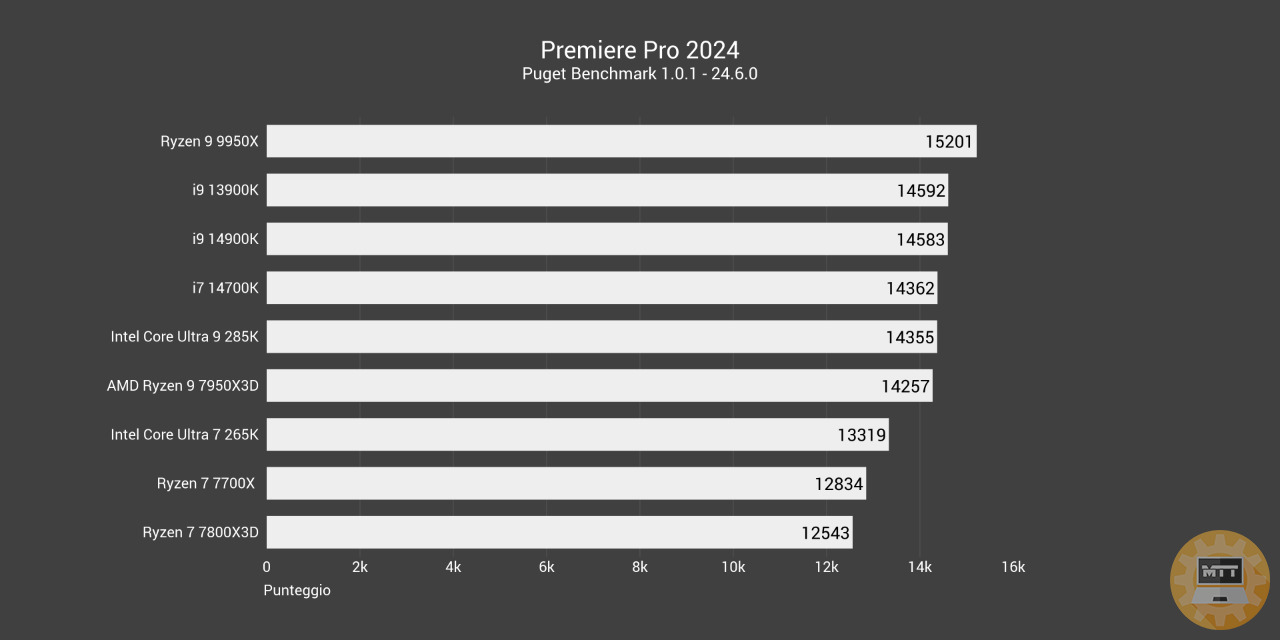
Premiere Pro 2024 #
Adobe Premiere Pro è un software di montaggio video in tempo reale basato su timeline, prodotto e distribuito da Adobe all’interno della raccolta Creative Cloud.
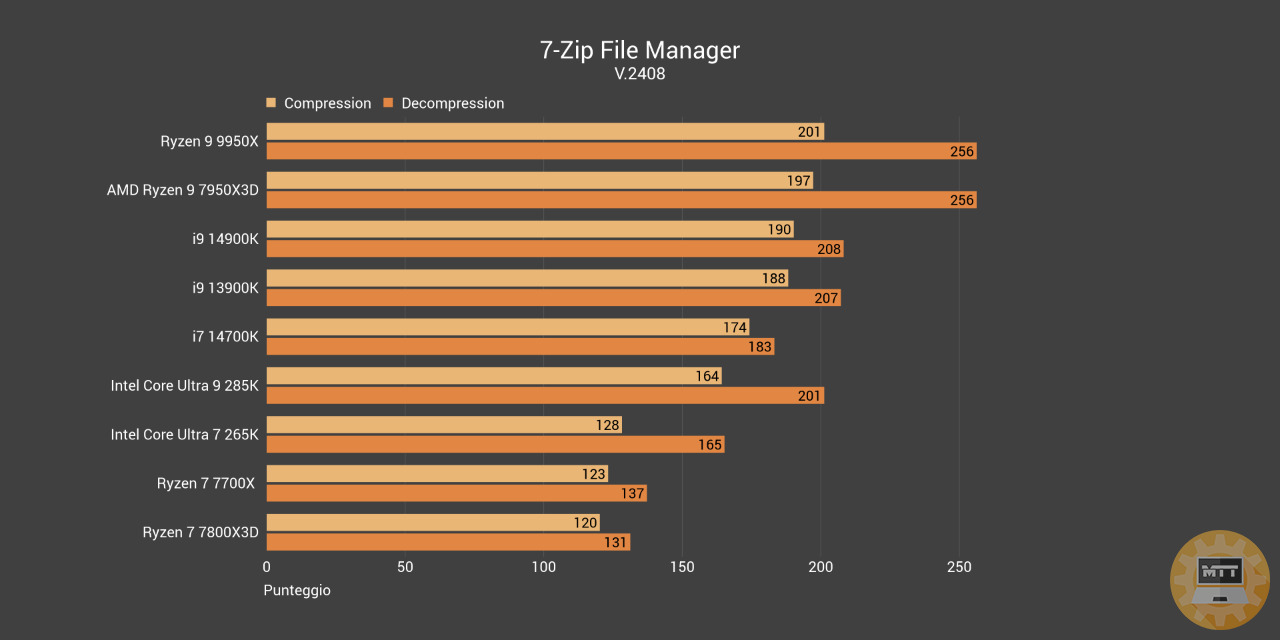
7-ZIP Manager #
7-Zip è un programma open source per la creazione e gestione di file compressi. Usa il proprio formato archivio 7z ma può leggere e scrivere in molti altri formati.
Questo test prova le performance dei processori in compressione e decompressione.
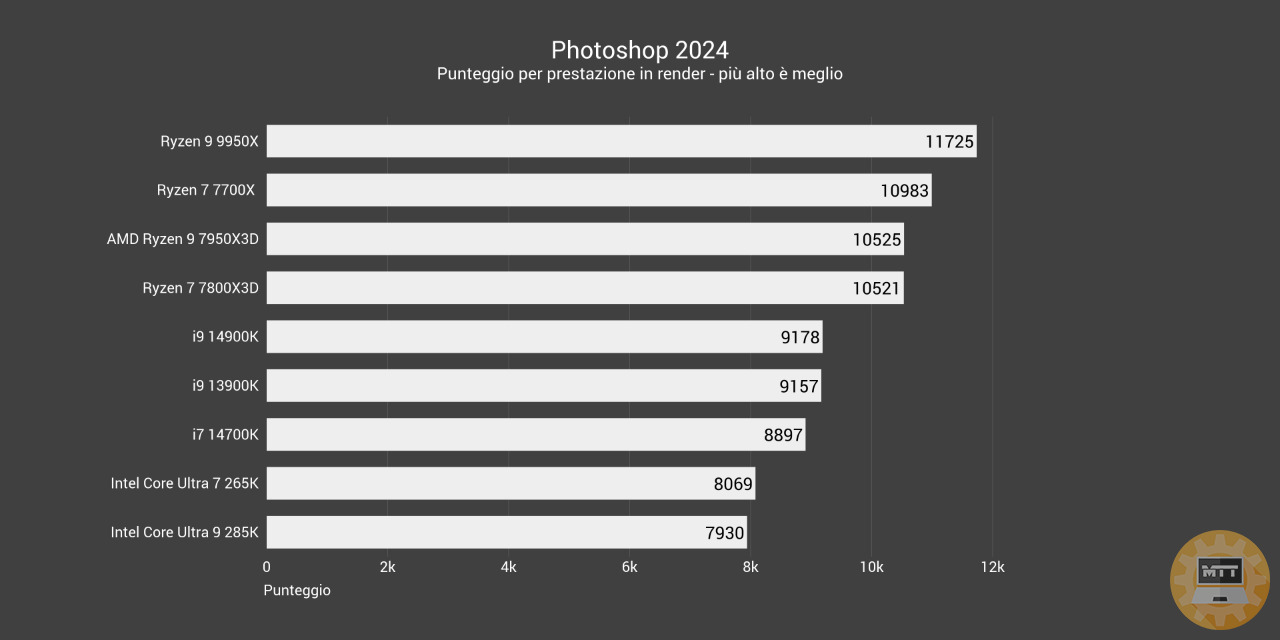
Photoshop 2025 #
Adobe Photoshop è un software proprietario prodotto da Adobe specializzato nell’elaborazione di fotografie e, più in generale, di immagini digitali.
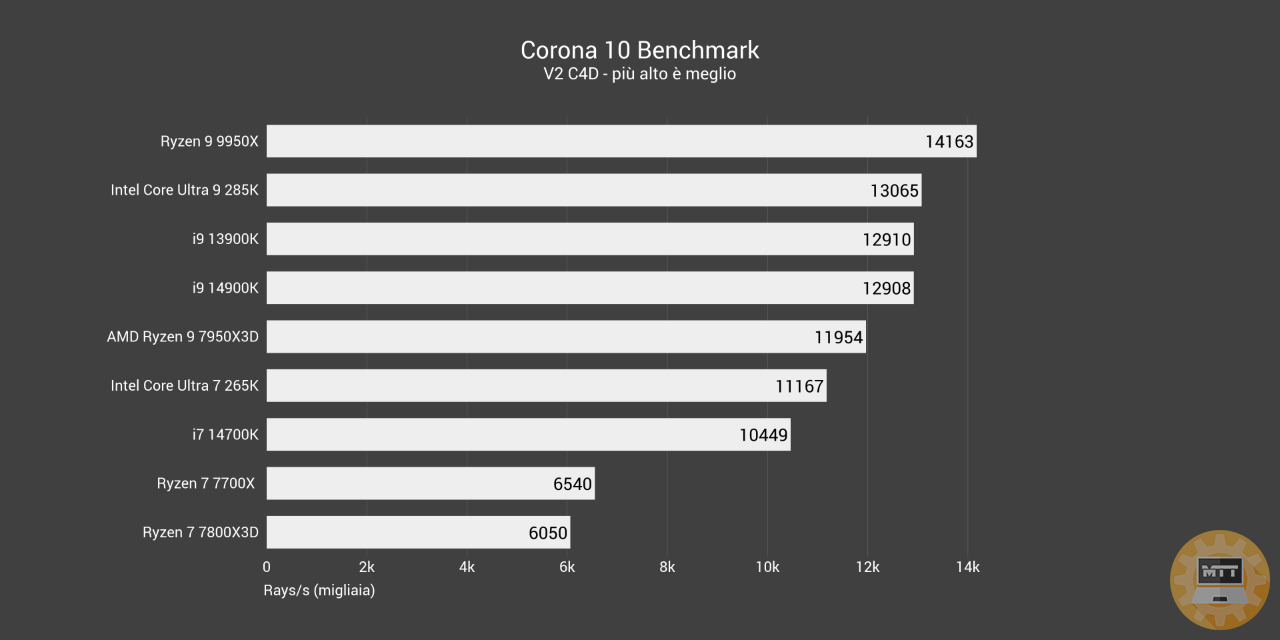
Corona 10 #
Chaos Corona è un software di rendering 3D di immagini generate al computer sviluppato da Chaos Czech, una filiale di Chaos.
Test con RAM diverse da 7200 e 8200 MHz #
Grazie ai kit in nostra dotazione abbiamo potuto esaminare le differenze prestazionali del 265K in caso si abbinino dei banchi di RAM più performanti nell’ambito del gaming e della produttività.
Timing RAM #
- 2x16 Corsair Dominator Titanium 6000 MHz CL 30 - 36 - 36 - 76
- 2x16 Corsair Dominator Platinum 7200 MHz CL 34 - 44 - 44 - 96
Test Produttività con RAM da 7200 MHz #
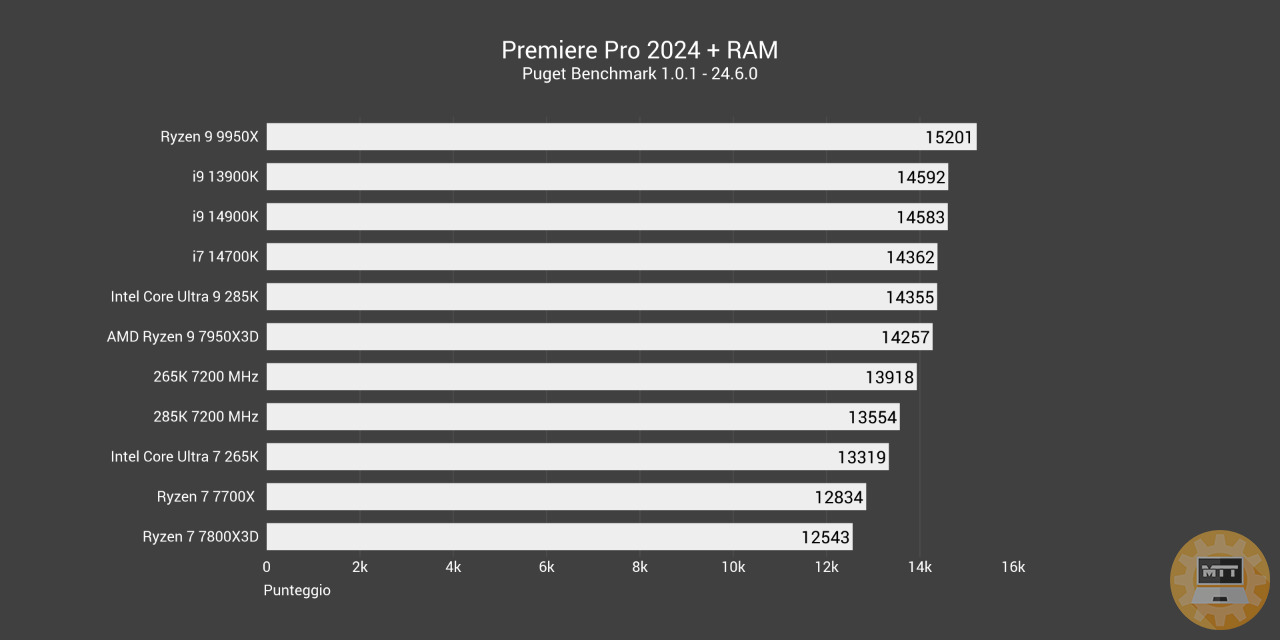
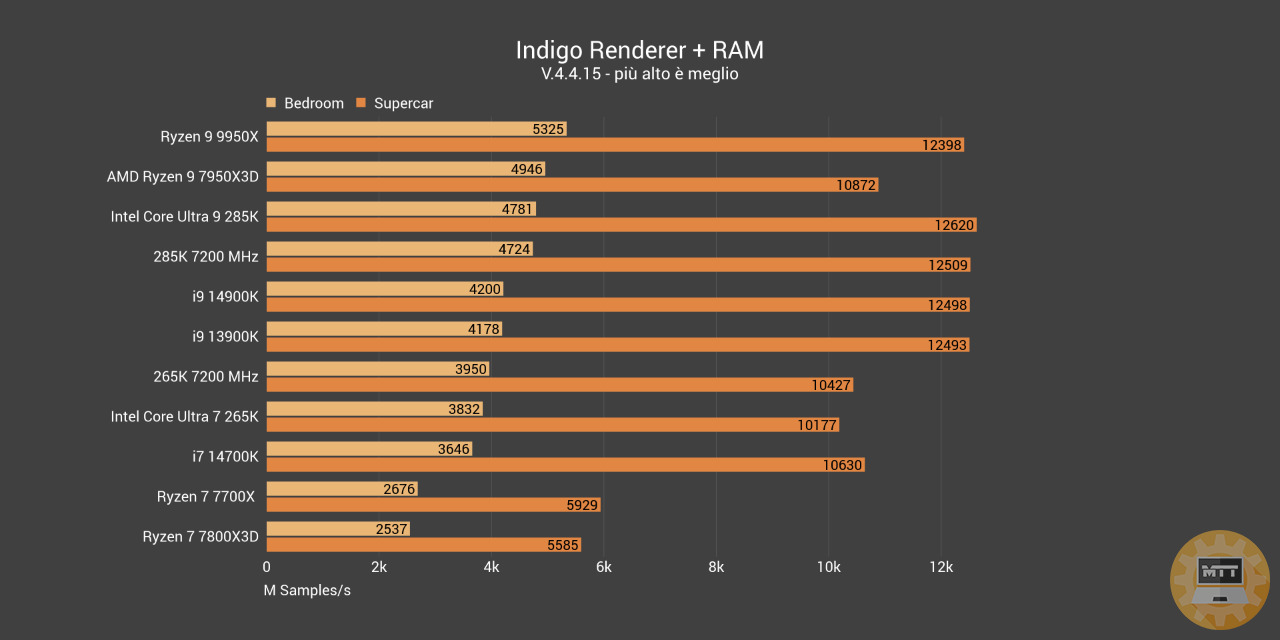
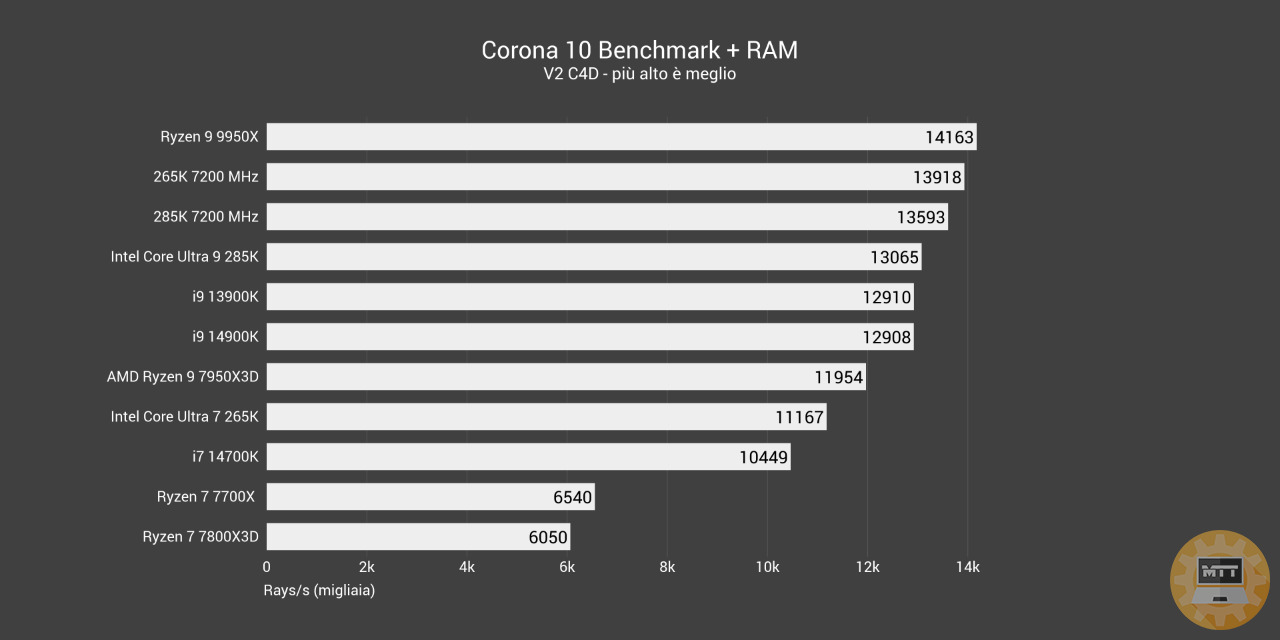
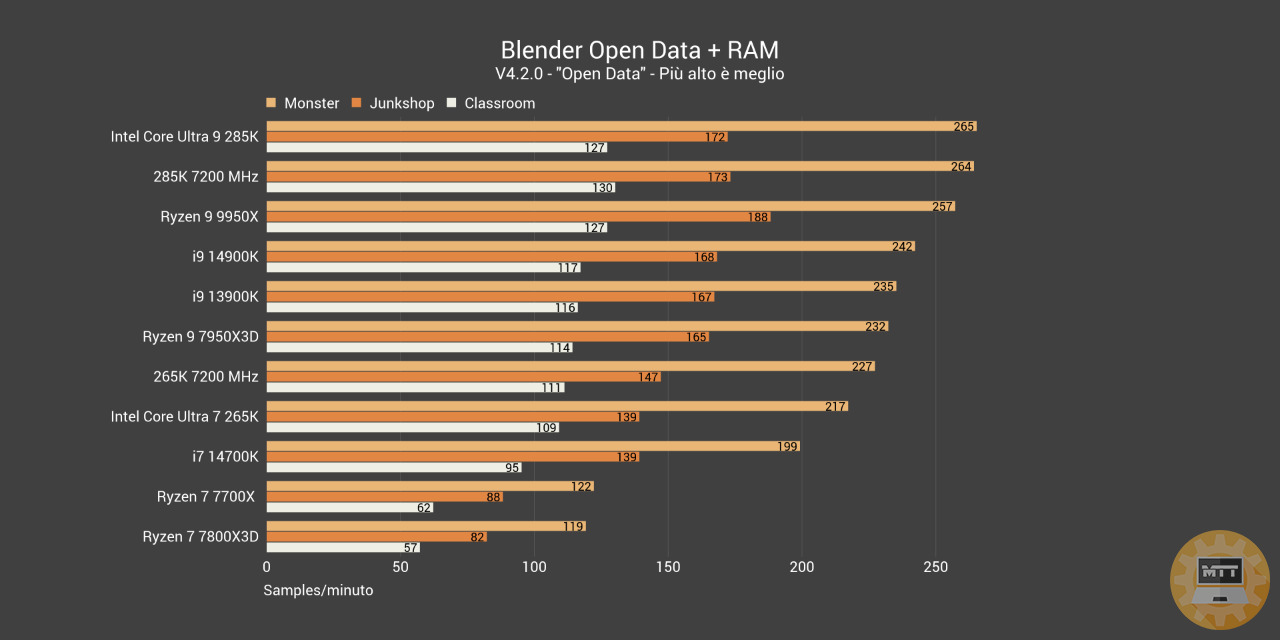
Il 265K in questo caso ha un guadagno netto nell’utilizzo delle RAM da 7200 MHz, complici anche i timing abbastanza buoni di questo kit di Corsair. Il 285K invece guadagna pochissimo o addirittura perde prestazioni in casi come Premiere Pro. Si potrebbe decisamente sottolinare qualche incompatibilità con Windows o un lancio troppo immaturo.
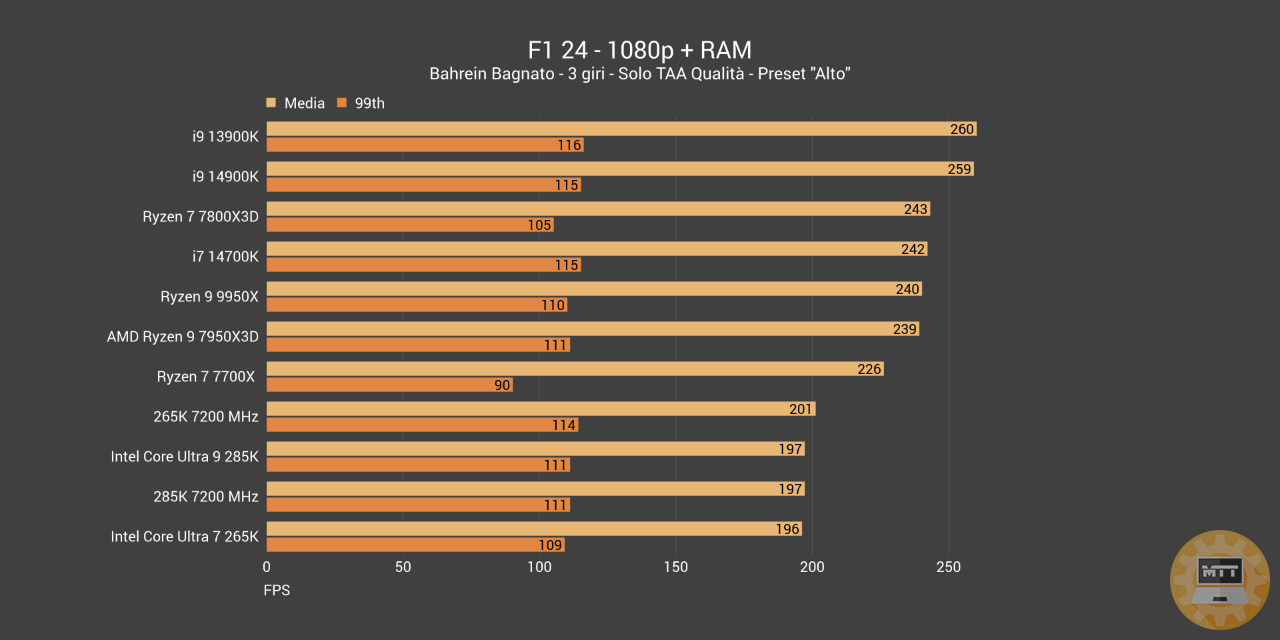
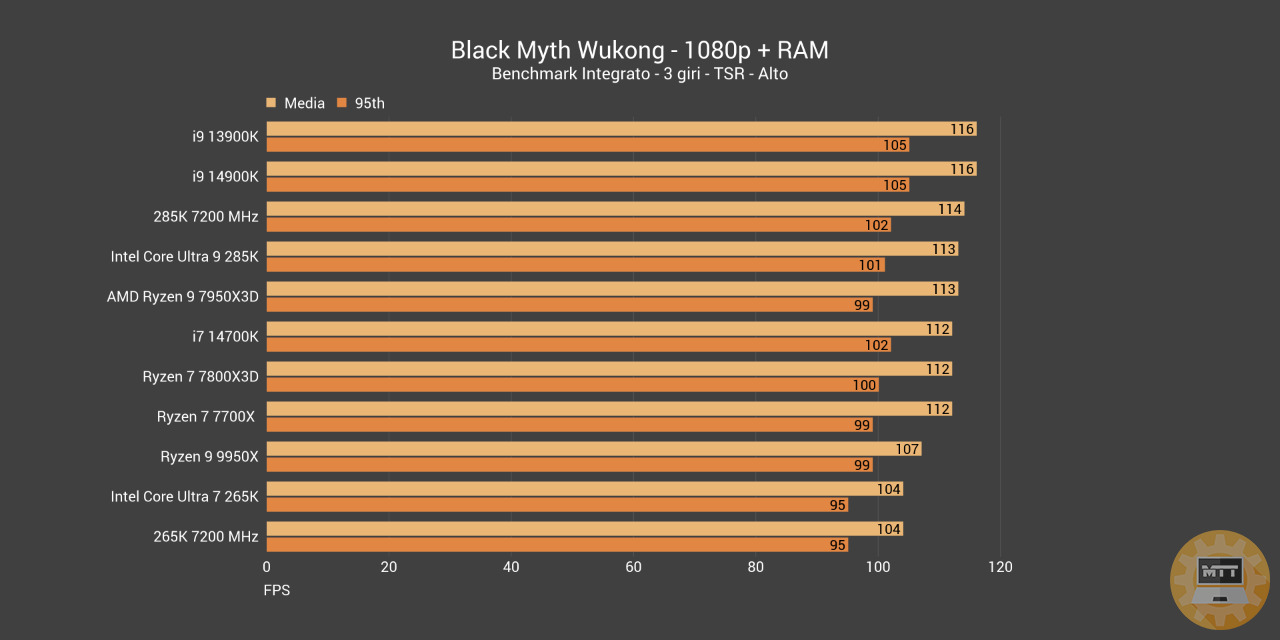
Test Gaming con RAM da 7200 MHz #
Nel contesto del gaming le RAM da 7200 MHz danno un leggero vantaggio al 265K, anche se questo vantaggio extra non riesce a posizionarlo meglio rispetto al 7700X nella maggior parte dei casi. Tuttavia sarebbe assolutamente giusto considerare questa come la frequenza “Sweetspot” per la nuova generazione Intel. Almeno per il 265K. Nel caso del 285K invece il vantaggio è nettamente risicato, molto vicino a quello originale ottenuto con 6000 MHz.
Abbiamo rimosso le RAM da 8200 MHz perché prive di risultati concreti come dimostrato nei grafici della recensione dell’Intel Core Ultra 265K.

Consumi e temperature #
La nuova generazione di Intel ha dei benefici indubbi nel contesto dell’efficienza energetica rispetto alla precedente generazione. Bisogna però paragonarla anche all’offerta attuale di AMD, specialmente con i modelli X3D e il loro totale predominio gaming.
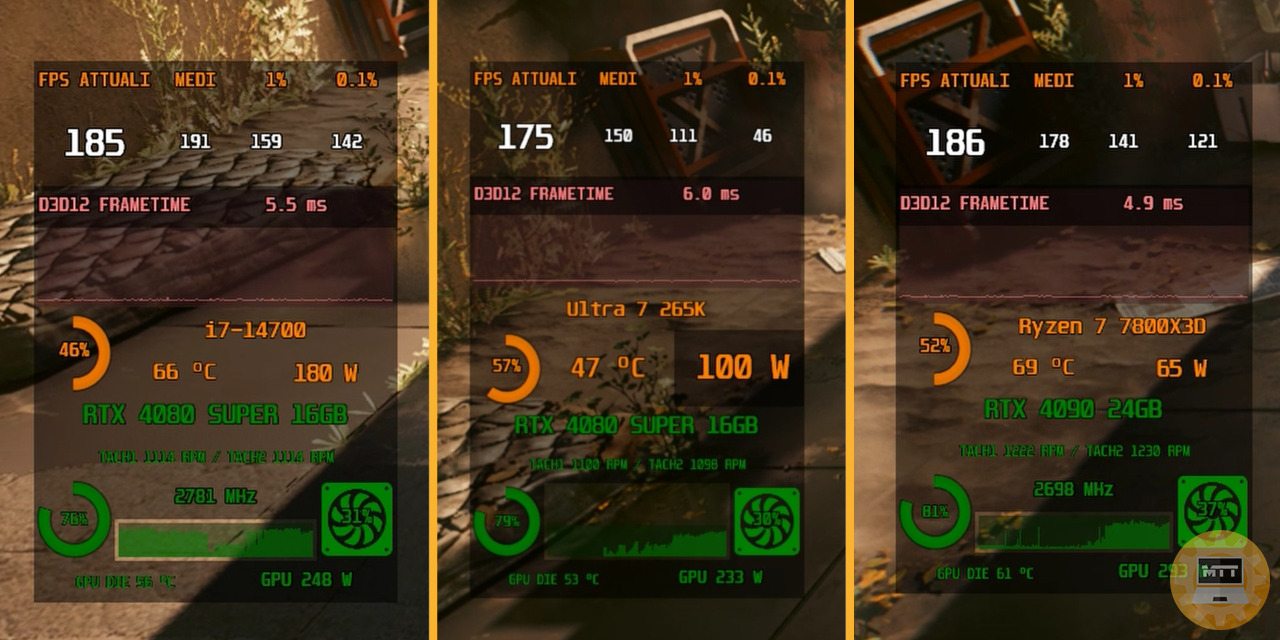
Ed è proprio lì che bisogna mettere i puntini sulle I. In questo screenshot preso dal nostro video completo, possiamo vedere come il 265K sia in grado di offrire dei consumi nettamente inferiori al 14700 liscio (che qui usiamo come paragone solo perché uno dei processori meno aggressivi della generazione). Si passa da 180-200W di picco a soli 80-100W. In pratica un 50% in meno, che è davvero notevole. Anche le temperature sono incredibilmente più basse.
Ma se messo a paragone con il 7800X3D, che ottiene delle performance anche migliori, questa efficienza perde di spessore. A sua volta il processore di AMD è capace di erogare prestazioni da top di gamma con un consumo dalle 2 alle 3 volte inferiore rispetto al 14700. E comunque ridotto rispetto a quello del 265K.
Ma l’efficienza non è il solo consumo, ma il rapporto tra la prestazioni ottenuta per il consumo speso.
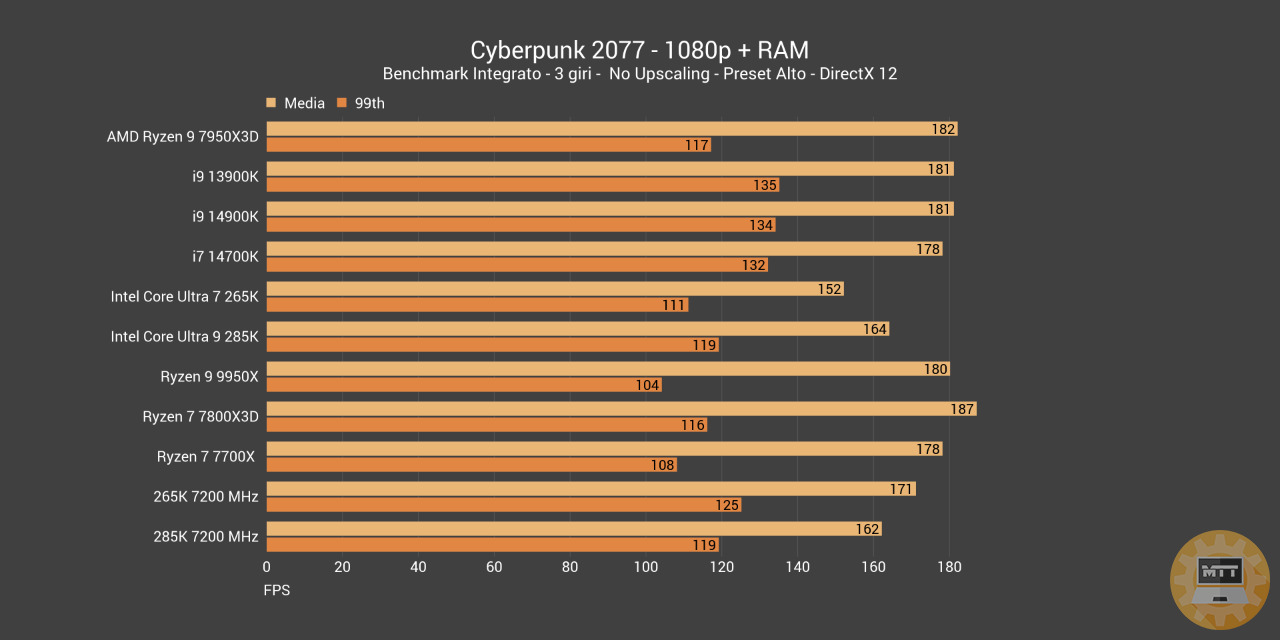
E considerando il grafico delle prestazioni qui sopra, abbiamo motivo per sottolineare come l’efficienza sia tutta a favore del 7800X3D di AMD.
Dall’analisi dei consumi nel contesto della produttività invece, con questo grafico di Premiere Pro possiamo analizzare il contesto del 285K contro il 13900K e 9950X.
Questo script di Puget Benchmark propone delle operazioni miste che i processori devono svolgere per concludere il test. Non c’è un tempo prestabilito e si valuta solo la prestazione effettiva nell’elaborare diversi contesti di video editing, encoding e decoding di elementi sulla timeline e altri aspetti della quotidianità di un video editor.
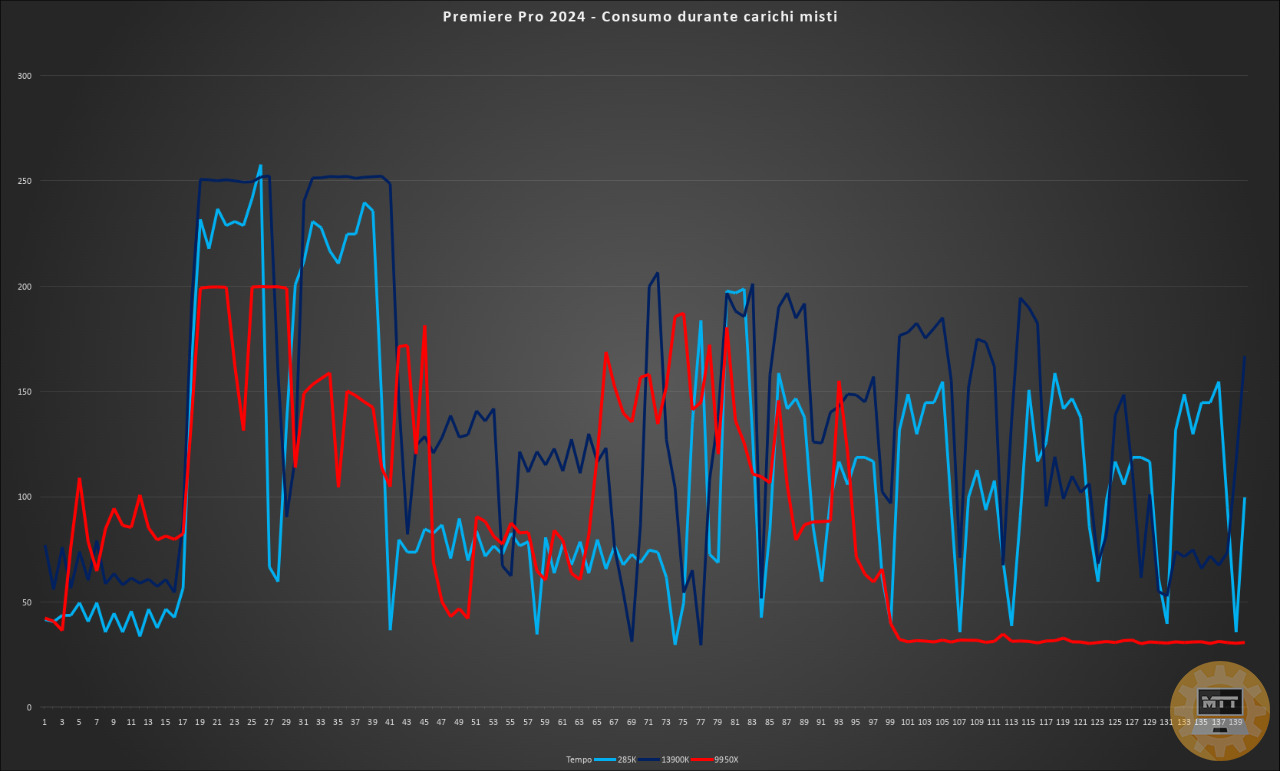
Come si può notare, il consumo medio del 9950X è nettamente più basso nella maggior parte delle operazioni, nonostante ottenga poi un punteggio migliore e come si può notare a fine grafico, concluda le operazioni in netto anticipo sui due processori Intel.
Pertanto anche sui top di gamma e nella produttività, l’efficienza energetica verte a favore di AMD.